Despite impressive natural language generation capabilities exhibited by large language models (LLMs), their applicability in specialised domains is hindered by error propagation, hallucination, and the challenge of reasoning across heterogeneous datasets. These limitations pose significant obstacles in domains where precision is paramount, such as health and finance. We explore language model augmentation with external tools, which has shown promise in mitigating these limitations, by offloading specific steps of the reasoning process to external tools better equipped for the task. More concretely, using financial domain question-answering datasets, we apply supervised fine-tuning on a LLaMA-2 13B Chat model to act both as a task router and task solver. The task router dynamically directs a question to either be answered internally by the LLM or externally via the right tool from the tool set. Our tool-equipped SFT model, Raven, demonstrates an improvement of 35.2% over the baseline, and is competitive with strong GPT 3.5 CoT and in-context learning baselines.
Inspired by the success of the Alpaca instruction-tuning protocol we use the instruction-tuned Llama 2 13B chat language model and fine-tune it further using the LoRA lightweight fine-tuning approach. For training we use a set of financial and generic structured and unstructured open-domain datasets to obtain a tool-augmented instruction following language model for finance, which we call Raven.
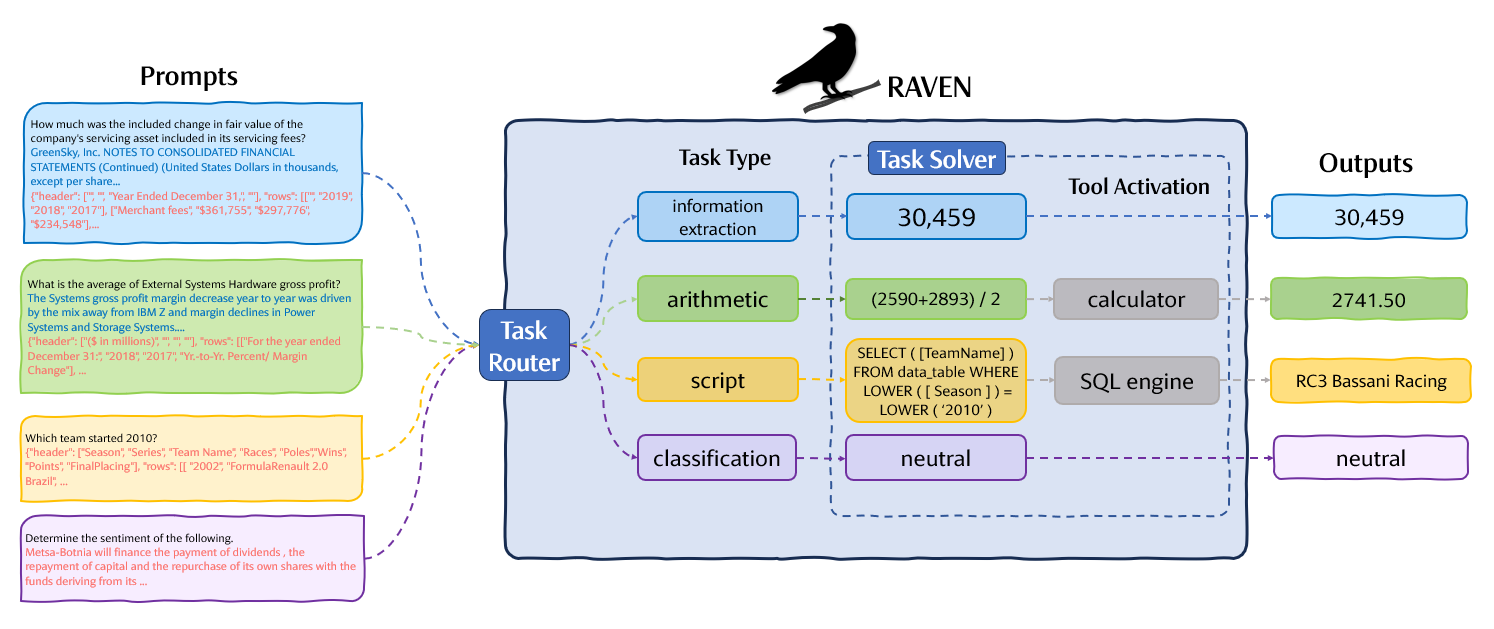
Inference pipeline. We use different prompt templates to steer Raven to either produce the final answer or produce an intermediate result, which is subsequently interpreted by one of the external tools.
Task-router. At inference time we prompt Raven twice for every query. Initially we wrap the prompt in a specialised 'template choice' prompt and expect the model to predict the best prompt template to use from 'arithmetic', 'classification', 'script' or 'information extraction', conditioned on the input.
Task-solver. The instruction, including the input and data if applicable, are wrapped in the prompt template that the model inferred and this is sent to Raven to generate the next output. Depending on the selected template the task router then invokes a tool to fulfill the request, or produces the response directly.
Calculator API. A calculator is instantiated in a python interpreter and is used to evaluate well-formed arithmetic expressions. The API expects one parameter representing the arithmetic expression and returns the evaluated result.
Lightweight database engine API. We create an API capable of executing SQL scripts on relational data. The API expects two parameters, (1) a string representation of the structured data in JSON format and (2) a SQL script. The API's internal lightweight database engine converts structured data from its textual form to the engine's internal relational representation and converts data types where applicable. The SQL script is executed on this internal representation and the API returns the resulting execution result.
| Dataset | ||||
|---|---|---|---|---|
| Model | OTT-QA | TAT-QA | Wiki-SQL | PhraseBank |
| GPT 3.5 (CoT) | 5.55% | 19.23% | 32.07% | 44.18% |
| GPT 3.5 (5-Shot) | 14.55% | 34.06% | 53.00% | 70.07% |
| +Tools | 14.60% | 46.82% | 75.88% | 71.73% |
| Llama 2 13B chat | 6.18% | 10.91% | 21.68% | 66.03% |
| +SFT | 20.10% | 37.87% | 74.38% | 90.97% |
| Raven | 16.03% | 51.35% | 84.25% | 91.92% |
| +Backoff | 16.03% | 52.27% | 85.52% | 91.92% |
Fine-tuning and using tools significantly improves performance. When compared to the base model Raven significantly improves the results on the PhraseBank dataset by an absolute 25.9%. These encouraging results suggest that even a limited dataset can endow a pre-trained language model with a sophisticated understanding of financial language, obtaining high accuracy in a financial sentiment classification benchmark.
On the Wiki-SQL dataset the base model is unable to infer the correct answer almost 80% of the time. This figure is inverted when the same benchmark is evaluated on Raven that obtains a 4-fold> improvement over the base model inferring the correct answer more than 85% of the time. Our model improves on the best GPT 3.5 performance by close to 10% (absolute). All the questions in this dataset can be addressed using the lightweight database engine and involve a combination of data selection, ranking and arithmetic operations on structured data. This result underscores the distinct advantage of delegating this task to a tool rather than relying on the language model to infer the results in a zero-shot manner. Despite the results not being as strong as Raven we observe a similar pattern on the GPT 3.5 evaluation in which better results are incrementally obtained when including examples in the context and using tools compared to Zero-Shot-CoT.
We see a similar pattern on the TAT-QA benchmark with the tool augmented model achieving a 5-fold improvement on the base model. Approximately 46% of the observations of the TAT-QA dataset are annotated with an intermediate arithmetic derivation that Raven evaluates using a calculator at inference time. In the analysis section we outline a comparative analysis to explore whether our model performs better on this partition of the data.
The majority of questions in OTT-QA require multi-hop inference involving both tabular data and unstructured text, with the information needed to answer the questions dispersed differently across these two input types. The baseline model from Chen at. al., which employs an iterative retriever and a BERT-based reader, attains an exact match score of less than 10%. This dataset does not have annotated intermediate steps to get to the answer and therefore all models are expected to infer the answer in a zero-shot manner without using tools. Despite Raven achieving an increase in experimental accuracy compared to the base model the relatively low score underscores the importance of intermediate reasoning steps and tools.
Backoff. We employ a backoff mechanism when Raven produces malformed expressions and fallback to the result obtained from the SFT model. This mechanism improves the results of datasets that employ tools at inference time: TAT-QA (51.35% → 52.27%) and Wiki-SQL (84.25% → 85.52%).
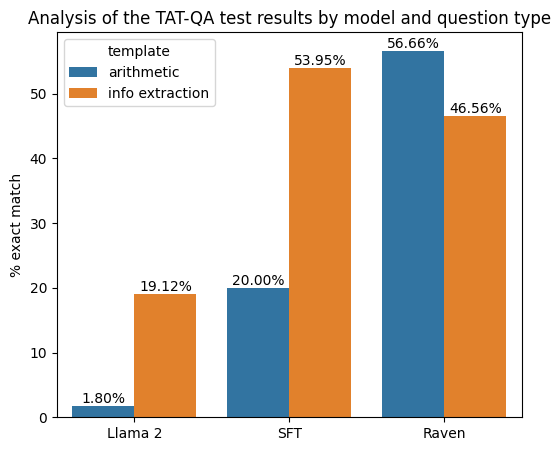
One model or many?. To assess the performance penalty of mixing all the datasets and training one multi-tasking model, we also train a model exclusively on the TAT-QA dataset. The evaluation result for this dedicated model on the TAT-QA dataset is 54.70%, which is 2.4% higher than Raven. We contend that this modest performance gain does not justify the overhead associated with maintaining separate models and switching between them during inference.
The effects of tool augmentation. Approximately half of the questions within the TAT-QA dataset are annotated with an arithmetic equation. The presence of the equation implies that the language model needs to perform multi-hop reasoning to output the correct answer. This process involves the correct extraction of, at a minimum, two numerical values from the context, followed by the execution of an arithmetic operation, such as addition or division. This particular scenario is ideal to understand the effect of SFT and tool augmentation, by comparing the performance of different models on the two categories of data from the same dataset.
We observe that SFT models are able to accurately extract multiple data points from the context, but require external tools to correctly compose the final answer from the gathered data. As shown in the above Figure the base model without any fine-tuning is ill-equipped to perform multi-hop reasoning achieving close to 2% accuracy (blue column) equating to ten correct answers of approximately 620. Although we observe an improvement in the SFT model, the impact of using tools is evident in the substantial jump to 56.7% accuracy achieved by Raven. Additionally, the consistent performance of the 'Information Extraction' type questions between SFT and Raven (orange column), which only requires data extraction to answer the question, continuous to re-enforce this observation.
The utility of augmenting language models with external tools is substantiated further through a comparative analysis of experimental outcomes on two similar datasets. Addressing questions on Wiki-SQL and OTT-QA requires multi-hop reasoning across diverse forms of data, spanning both structured and unstructured formats. The primary difference lies in the annotation method: the Wiki-SQL dataset is annotated with a data extraction script which, when executed on the structured data, yields the answer. In contrast, the OTT-QA dataset lacks this intermediate derivation step. By delegating the script execution to an external tool, Raven achieves an exact match accuracy of 85.52% on Wiki-SQL and 16.03% on OTT-QA, underscoring the effectiveness of fit-for-purpose external tools in this scenario.
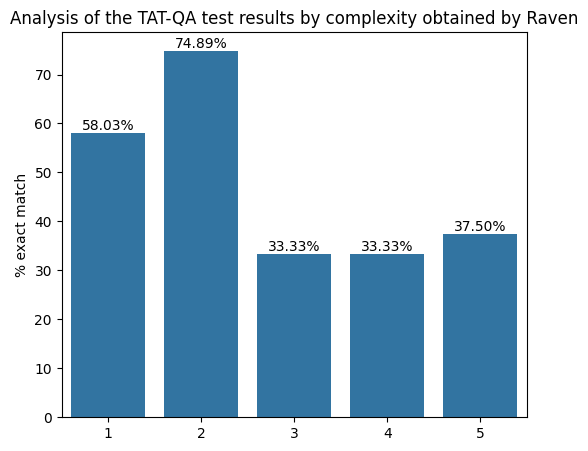
Question complexity. On the TAT-QA dataset we can use the number of arithmetic operators in the gold evaluation as a proxy for question complexity. One arithmetic operator implies the extraction of two numerical values from the context, two operators, three numerical values, and so on. As shown in the above, model performance degrades with the number of operators (x-axis) and hence the numerical values required to be extracted from the context.
Hardware bottleneck. Our experiments were constrained with fitting our model on available commodity hardware. We hypothesise that it would be possible to obtain better performance using the larger Llama 2 70 billion-parameter model and a longer context length.
Language model evaluation. Our experimental results demonstrate that evaluating natural language generation models (NLG) in a domain characterised by the ubiquitous presence of numerical values, such as finance, poses a significant challenge. Mainstream NLG evaluation metrics provide a measure of similarity between generations which is reported in terms of surface form similarity. These measures are not suitable for comparing numerical content. For example the candidate and reference sentences "The amount of goodwill reallocated to the IOTG operating segment in 2018 was $480 million", and "The amount of goodwill reallocated to the IOTG operating segment in 2018 was $480" have a BERTScore of 99.17%! Conversely, using exact match criteria might unjustly penalise NLG models, given that identical numerical values can be expressed in varying forms - such as "$4 million" and "$4,000,000," or "0.24" and "24%,". In some cases, numerical values can be integrated within a passage of text, rendering the evaluation of such content very challenging.
GPT-3.5 evaluation. Evaluating our benchmark with GPT 3.5 poses significant challenges, particularly when using chain-of-though reasoning. GPT-3.5 does not consistently adhere to instructions for providing a concise response, such as a single word or number, which makes exact match comparisons challenging. Additionally, we have noticed that GPT 3.5 does not generate a response when uncertain. This is particularly evident when evaluating the PhraseBank dataset, which does not exhibit common sentiment negative or positive words.
Through a series of experiments we have demonstrated the feasibility of extending a small scale open foundation model into the financial domain. We obtain a new model, Raven, by leveraging Llama 2 13B chat and use a relatively small and diverse dataset to fine-tune a mere 0.2% of its parameters. Raven remarkably elevates the performance of the base model from 2% to 56.7% on the TAT-QA arithmetic question answering benchmark. On average, across the datasets we experimented with, Raven lifts average absolute performance by 35.2% compared to the base model, surpassing even a significantly larger GPT 3.5 model by 9.2%. Additionally, through a comparative analysis of question answering datasets we demonstrate the effectiveness of augmenting language models with external tools, showing significant improvements in accuracy when addressing multi-hop questions with tools.
Future work. The financial domain encompasses not only structured and unstructured data but also the pervasive presence of visual representations of data in charts. To develop a comprehensive financial language model, it becomes imperative to endow these models with the capability to engage in multi-modal reasoning. Additionally, in our pursuit to create specialised domain AI assistants, our efforts should extend beyond enhancing their predictive capabilities. While it is undoubtedly crucial to push the boundaries and surpass previous state-of-the-art achievements, we believe it is equally imperative to equip language models with the capacity to quantify uncertainty. Is it possible for a tool-augmented model to report a measure of certainty with its generated result? We leave multi-modality and certainty quantification for future work.
@inproceedings{theuma-shareghi-2024-equipping,
title = "Equipping Language Models with Tool Use Capability for Tabular Data Analysis in Finance",
author = "Theuma, Adrian and
Shareghi, Ehsan",
editor = "Graham, Yvette and
Purver, Matthew",
booktitle = "Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = mar,
year = "2024",
address = "St. Julian{'}s, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.eacl-short.10",
pages = "90--103",
abstract = "Large language models (LLMs) have exhibited an array of reasoning capabilities but face challenges like error propagation and hallucination, particularly in specialised areas like finance, where data is heterogeneous, and precision is paramount. We explore the potential of language model augmentation with external tools to mitigate these limitations and offload certain reasoning steps to external tools that are more suited for the task, instead of solely depending on the LLM{'}s inherent abilities. More concretely, using financial domain question answering datasets, we apply supervised finetuning on a LLAMA-2 13B CHAT model to act both as a task router and task solver. The task router dynamically directs a question to either be answered internally by the LLM or externally via the right tool from the tool set. Our tool-equipped SFT model, RAVEN, demonstrates an improvement of 35.2{\%} and 5.06{\%} over the base model and SFT-only baselines, respectively, and is highly competitive with strong GPT-3.5 results. To the best of our knowledge, our work is the first that investigates tool augmentation of language models for the finance domain.",
}